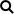
Blog Post < Previous | Next >

Goh
The Diagnostic Challenge: AI vs Doctors
Introduction
To evaluate how well Large Language Models (LLMs) can diagnose health conditions vs doctors, I refer to three recent papers:
- Hager paper using a “Clinical Decision Making” framework, January 26, 2024 [1]
2. Goh paper using a “Diagnostic Reasoning” framework, 2024. Test period November 29 to December 29, 2023 [2]
3. McDuff paper using a “Accurate Differential Diagnosis” framework, November 2023 [3]
The Hager paper framework is the most challenging regarding agency as it required the LLMs to make discretionary decisions such as requesting physical exams and lab tests, and follow medical guidelines. It tested 5 open source LLMs (Llama Chat 2, and several variations of it).
The Goh paper is more focused on diagnosing alone. It required participants to make 3 differential diagnoses per case. It also included many qualitative factors to such diagnoses assessment. It tested a powerful proprietary LLM: Chat GPT-4.
The McDuff paper is the most challenging on diagnostic analysis factors as it focused on complex conditions where the doctors had to render differential diagnoses (minimum of 5 and up to 10 per case). The latter entailed generating a list of up to 10 potential diagnoses ranked from most likely to least likely. The McDuff paper also included many qualitative factors, similar to the Goh one, to assess the quality of the diagnoses. It tested a powerful proprietary LLM: a derivative of Gemini trained on medical data.
The three papers conducted their respective testing near the end of 2023. Thus, it reflects the performance of LLMs at the time.
Summary findings
The Hager paper showed that the open source LLMs were pretty much worthless on all counts.
The Goh paper testing a far more powerful proprietary LLM, Chat GPT-4, uncovered that its performance far surpassed the doctors. And, the doctors, somehow, did not benefit from using Chat GPT-4.
The McDuff paper also tested a very powerful proprietary LLM, a derivative of Gemini trained on medical data. It also performed far better than doctors. But, contrary to the Goh paper, this paper demonstrated that doctors using the LLM performed better than otherwise, but still not as well as the LLM alone.
Hager paper. Clinical Decision Making [1]
The Hager paper experiment was different from the other two in several respects:
- They tested 5 different LLMs instead of just 1
- They tested only open source models (for data privacy considerations) The other two tested only a single LLM proprietary model.
- They tested the performance of doctors vs the LLMs. They did not test the performance of doctors assisted by LLMs. The other two papers did that too (testing the performance of doctors assisted by LLMs).
The Hager team used a very large data set of 2,400 cases, that occurred between 2008 and 2019, of four common abdominal conditions:
- Appendicitis
- Cholecystitis
- Diverticulitis
- Pancreatitis
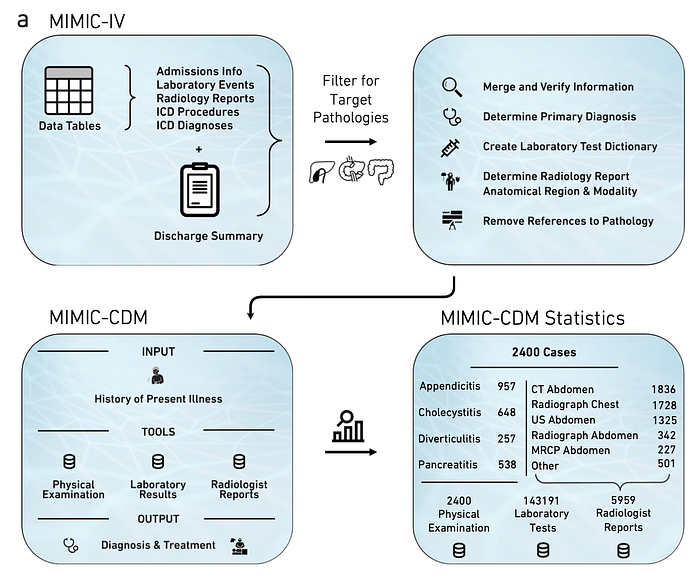
They tested 5 different open sources models, including 3 general models:
- Llama 2 Chat
- OASST
- Wizard LM
They also tested 2 specialized models trained on medical data:
- Clinical Camel
- Medtron
The Hager team just used 4 doctors to make 100 diagnoses randomly selected from the pool of 2,400 cases. Each doctor had to make 20 diagnoses for each of the abdominal conditions plus 20 for other abdominal conditions (gastritis, urinary tract infection, esophageal reflux, and hernia).
The Hager team called their testing framework “ Clinical Decision Making.” Thus, it entailed a lot more than just diagnosing. As part of their framework, they tested their models on 5 different dimensions of clinical decision making:
- Diagnostic accuracy
2. Clinical guidelines
3. Following instructions
4. Lab test interpretation
5. Robustness
The 2 specialized models trained on medical data could only be tested on diagnostic accuracy and not on any of the other four dimensions.
Diagnostic accuracy
The short answer is that all LLMs performed poorly compared to doctors.
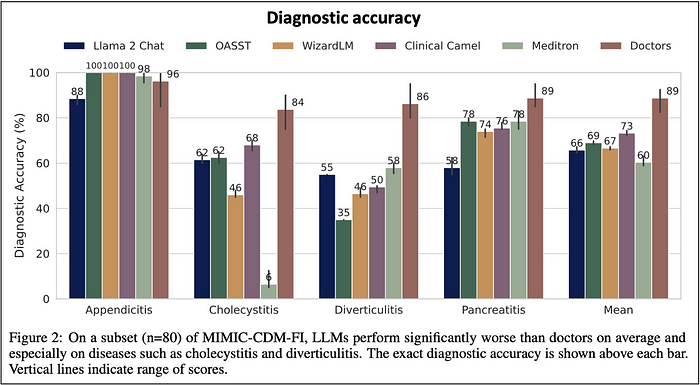
From the above visual data, we can extract the results comparing directly Llama 2 Chat (the most renowned of the general open source LLM tested) vs doctors. And, Llama 2 Chat’s diagnostic accuracy looks really poor compared to doctors.
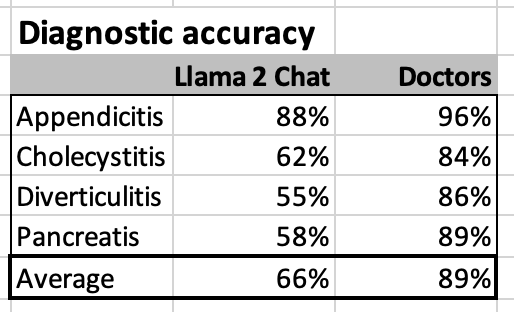
None of the other tested LLMs did markedly better than Llama 2 Chat.
Clinical guidelines
This was a challenging test asking the LLMs to emulate human like discretionary agency by requesting physical examinations and order the necessary lab tests to fully diagnose a condition. As shown on the visual data below, the LLMs did not undertake these discretionary decisions well.
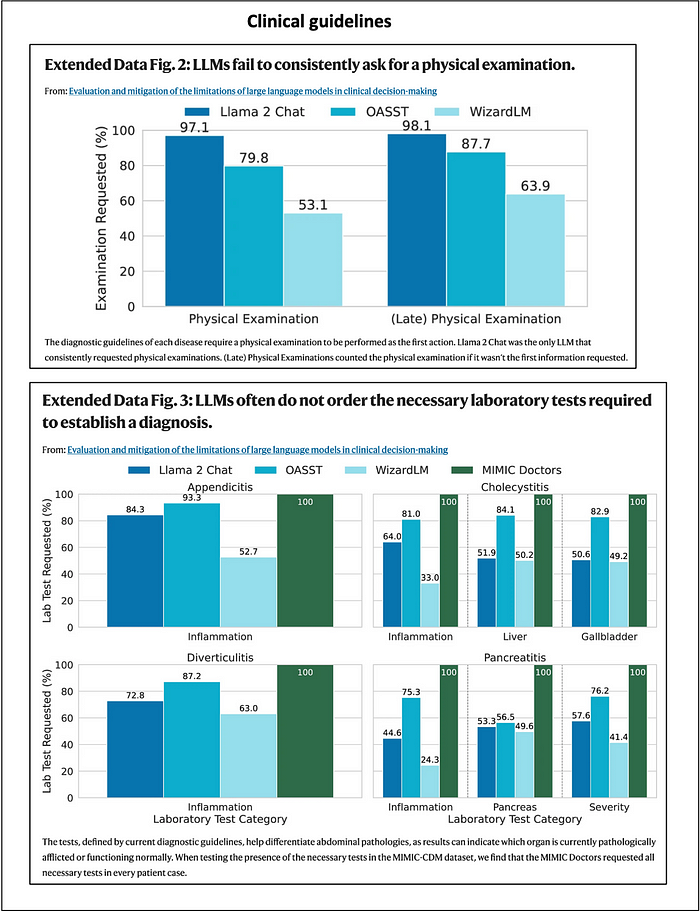
Following instructions
This was another human discretionary decision or implementation test. Again, the LLMs did not perform well in such instances, and made many errors.
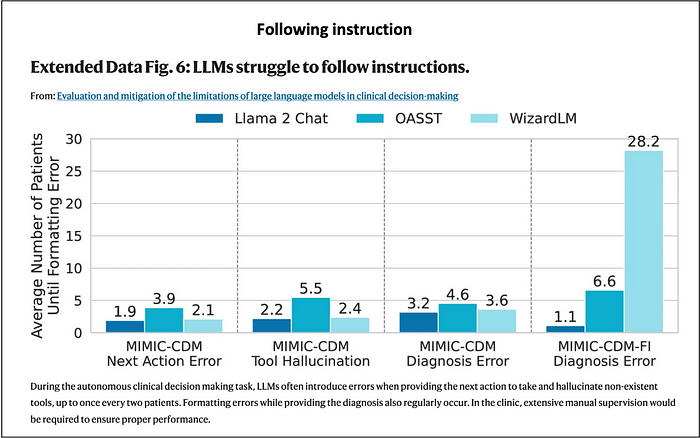
The above data is a little bit difficult to interpret. So, I converted the metrics into an error rate in %. Making an error every two patients corresponds to an error rate of 50%. That’s not good.
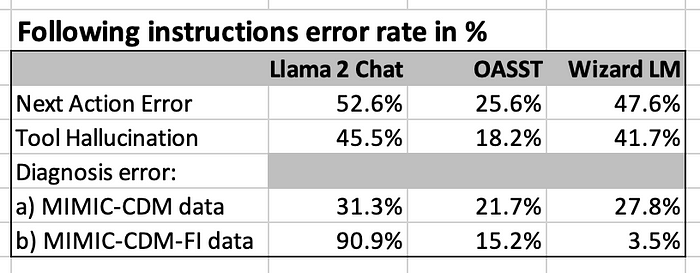
Lab test interpretation
It is baffling that the specialized LLMs trained on medical data were not able to handle lab test interpretation. The general LLMs did not handle this task well.
Within the graph below, the key is how badly the LLMs did in identifying out-of-range lab test results, either Low or High.
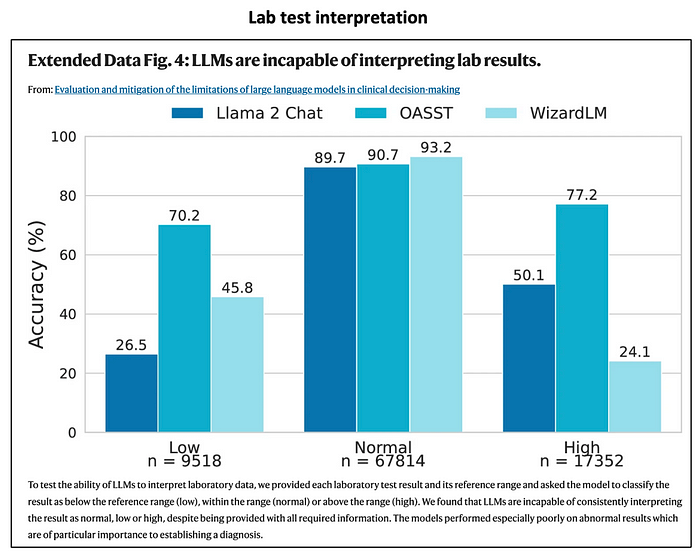
Next, I translate the above data into false negative rates in %. As shown below, the false negative rates are really high for Llama 2 Chat and Wizard LM. They are quite a bit lower for OASST.
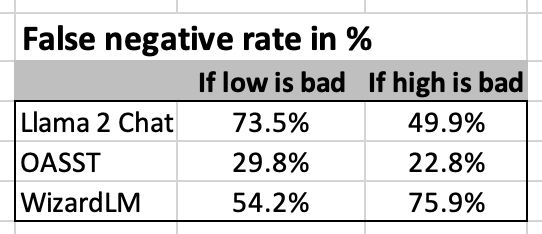
Even a layperson would easily perform a perfect false negative rate of 0%. You just have to read the lab results, and see if the figures are out of range on either the low or high side.
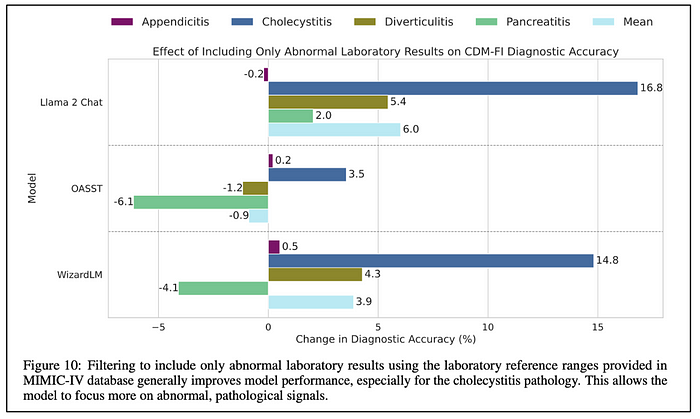
By eliminating all the lab test values within the normal range, the models were able to improve quite a bit. Llama 2 Chat and WizardLM show much more improvement just because their initial performance was so much worse than OASST.
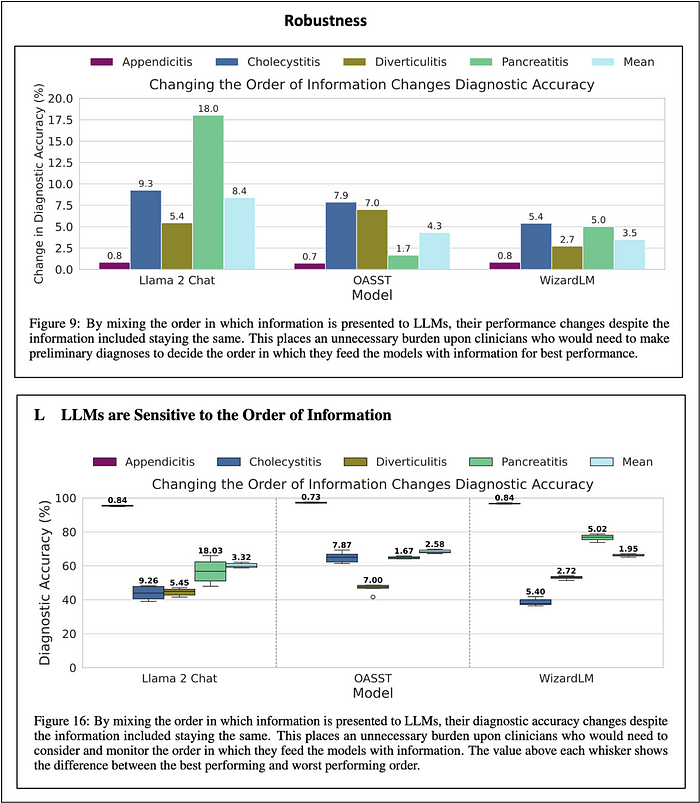
Robustness
The LLMs were pretty bad on that count. Changing the order of the information delivered to the LLMs could have a dramatic influence on their overall diagnostic accuracy. But, this order was different for each of the models. That’s a pretty unworkable situation.
Hager paper conclusion
The Hager paper demonstrated that the open source LLMs they tested were pretty much worthless in terms of “clinical decision making.” They were even unable to just read and interpret lab results accurately, a task that even a layperson could do easily.
Goh paper. Diagnostic Reasoning [2]
The Goh Team evaluated diagnostic reasoning based on overall diagnostic performance. The latter entailed:
- Differential diagnosis accuracy
- Appropriateness of supporting and opposing factors
- Next diagnostic evaluation steps
They rated the doctors diagnostic performance by generating a single score that captured all three mentioned criteria.
They tested the performance of 50 doctors. They were split into two groups:
- 25 of them consisted of the intervention group who used Chat GPT 4, a general LLM model, to assist them in making their diagnoses.
- 25 were part of the control group did not use the LLM, but used their standard search resources to make their diagnoses.
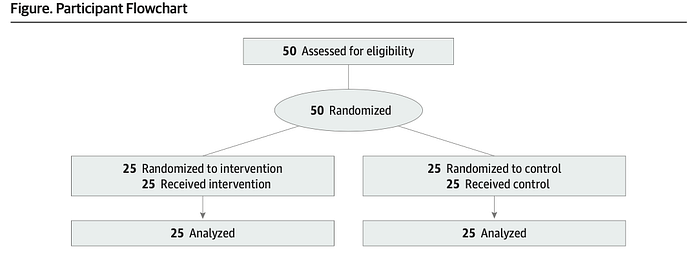
The doctors made 6 diagnoses within one hour.
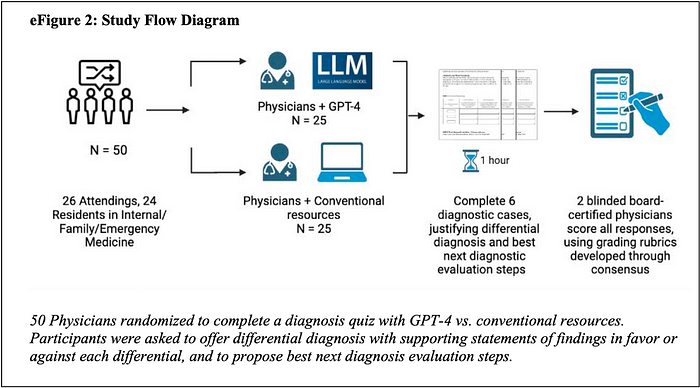
The Goh Team used the following Diagnostic — Structured Reasoning Grid.
Diagnostic performance score
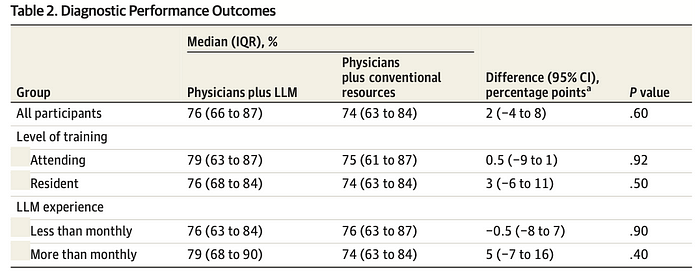
The main point of the table below is that the doctors within the intervention group who used Chat GPT-4 did not perform statistically better than the control group of doctors who used traditional search resources.
The box plot below is most revealing. While it shows that doctors who did use Chat GPT-4 (green box) did not do significantly better than the ones who did not (blue box), it does show that Chat GPT-4 alone (red box) did a heck of a lot better!
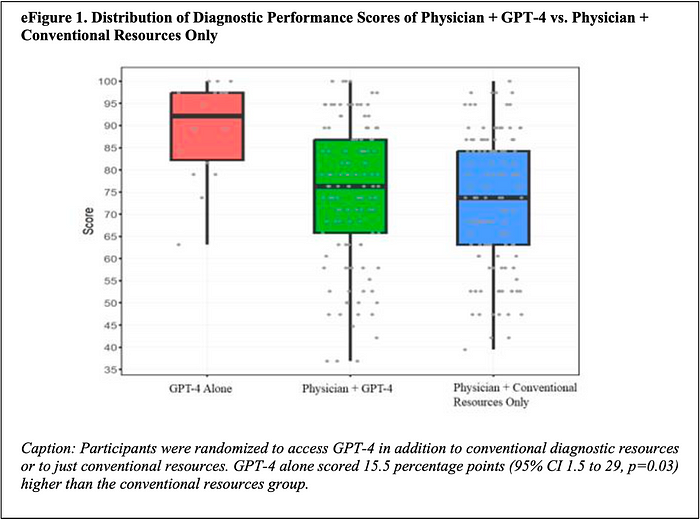
The table below discloses the underlying data captured visually within the box plot above.

Goh paper conclusion
Chat GPT-4 alone performed so much better than the doctors using Chat GPT-4. This entails that doctors make far more errors than Chat GPT-4 incurs hallucinations.
Doctors using Chat GPT-4 did not perform any better than the ones using just standard search resources.
In other words, the doctors did not benefit from using Chat GPT-4 instead of their standard search resources. But, that was not the fault of Chat GPT-4, it was the doctors’.
McDuff paper. Accurate differential diagnosis [3]
The McDuff Team is a Google Team. Google developed a specialized medical LLM called Med-Palm 2 that is a derivative of their Gemini LLM.
The McDuff Team accurate differential diagnosis framework is similar to the Goh Team diagnostic reasoning framework. However, it is focused on challenging cases where the doctors had to generate a “differential diagnosis (DDX).” The latter entails generating a ranked list of potential diagnoses for each condition with the most likely diagnosis at the top of the list (the 2nd most likely in 2nd place, etc.). The doctors were required to generate DDX lists with at least 5 and up to 10 diagnoses. Within the Goh paper the doctors also did DDX. They had to come up with only 3 possibilities instead of 5 to 10 in the McDuff paper.

They evaluated the doctors’ diagnostic performance using similar criteria as the Goh Team. These included:
- Diagnostic accuracy
- Comprehensiveness
- Appropriateness
The 20 tested doctors were divided into two groups of 10. All doctors first advanced a list of baseline diagnoses for each cases without any assistance.
Next, one group of doctors used traditional search assistance to revise their diagnoses; while the other group used the LLM for assistance to do the same (Stage 1 in the picture below).
Stage 2 is the evaluation step where specialists generate a gold standard DDX, and then evaluated the following DDX performances:
- doctors alone
- doctors using search
- doctors using the LLM
- LLM alone
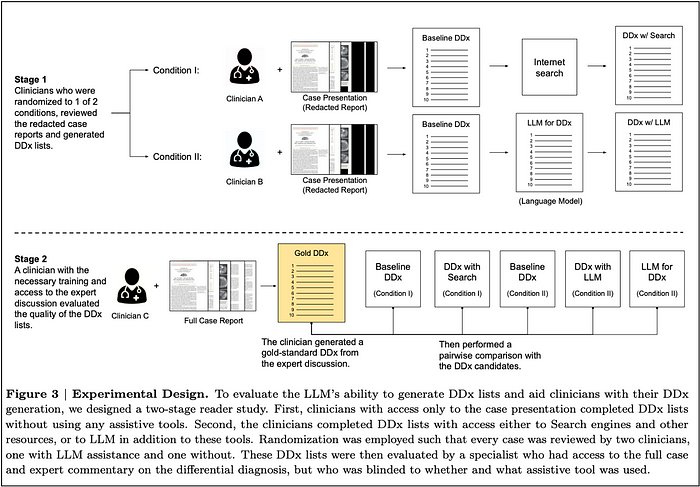
The doctors were asked to come up with a ranked list of at least 5 and up to 10 different diagnostics for each case. This entailed that the 302 cases used for testing were very challenging. These were published in the New England Journal of Medicine between 2013 and 2023.
Together the 20 doctors diagnosed the 302 condition-cases. So, each made about 15 differential diagnoses.
Diagnostic accuracy
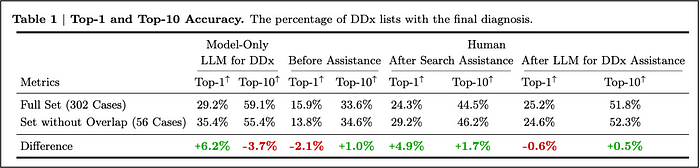
To measure diagnostic accuracy, they measured whether a doctor had listed the correct diagnosis as the most likely at the top of their list (top-1 accuracy). Otherwise, if a doctor had included the correct diagnosis among their top 2, they called it top-2 accuracy. They did so all the way to top-10 accuracy.
The table below discloses the diagnostic accuracy performance at the top-1 and top-10 accuracy level for the LLM only, the doctors before assistance and after assistance with either regular searches or the LLM. The table also differentiates between two data sets. The first one includes all 302 cases, the second one excludes 56 cases that may have been used in training the Med-Palm 2 LLM. This data segmentation did not have a material impact on the result.
The graphs below are most informative because they display the entire curve of diagnostic accuracy from top-1 to top-10 accuracy. The graph on the left used an automated evaluation using the Med-PaLM 2 LLM. The graph on the right, used specialists to make the same diagnostic accuracy evaluation.
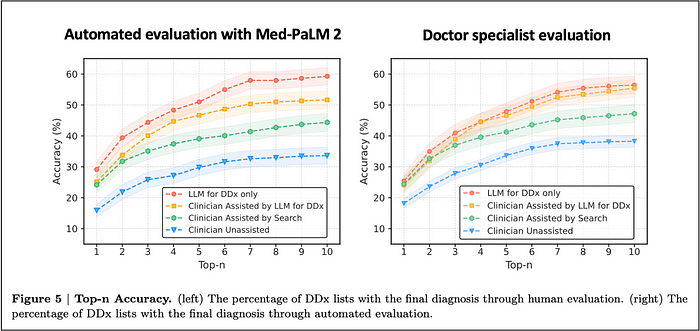
The two graphs above look very similar. However, the automated evaluation using the Med-PaLM 2 LLM is much more differentiating between the various groups. You can observe the automated evaluation greater differentiation in several ways:
- First notice the much greater space between the blue line (doctors without any assistance) at the bottom and the red line (LLM only) at the top.
- Second notice the far greater differentiation between the red line (LLM only) vs the orange line (doctors + LLM). Within the automated evaluation, there is a marked gap between the two. Within the evaluation conducted by the specialists, the red and orange line nearly overlap.
The Mc Duff Team also represented the diagnostic accuracy of 5 different groups using the diagrams below. They now look at 5 groups because they separated the unassisted doctors who would next use the LLM from the unassisted ones who would next use traditional search resources.
Every which way you look at it, you find the same performance hierarchy:
- The LLM does best
- Doctors assisted with the LLM come in second
- Doctors assisted with standard search resources come in third
- Doctors unassisted come in last
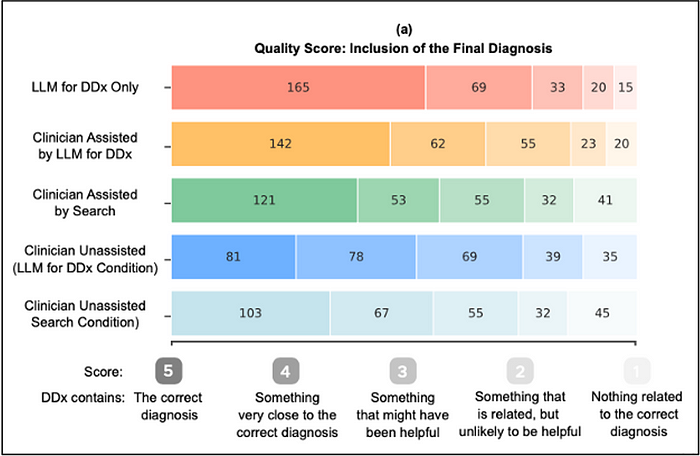
Quality
The diagram below shows a qualitative assessment whether a doctor or the LLM made the correct diagnosis, or came close to it, or entirely missed the boat. The doctors using the LLM (orange) did markedly better than the ones just using standard search resources (green) and the unassisted ones (blues).
Comprehensiveness
Here is a similar diagram on whether the doctors or the LLM listed all most reasonable diagnoses or not. The doctors assisted by the LLM arrived at more comprehensive differential lists compared to the ones using standard search resourses and the unassisted ones.

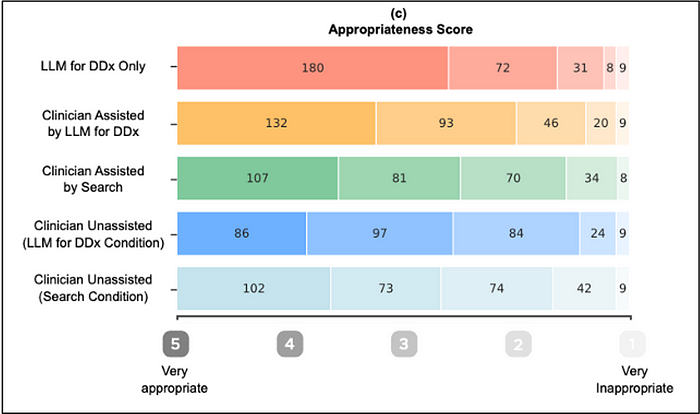
Appropriateness
Here is a similar diagram for appropriateness. The comments for comprehensiveness are relevant for appropriateness. You observe the exact same performance ranking with LLM alone being best, and unassisted doctors coming in last.
Combination of all three factors
Below I am summarizing much of the visual data above.
First, I am capturing the % of diagnosis receiving the top score in each category (Diagnosis, Comprehensiveness, Appropriateness) for the Chat GPT-4 LLM vs doctors unassisted.
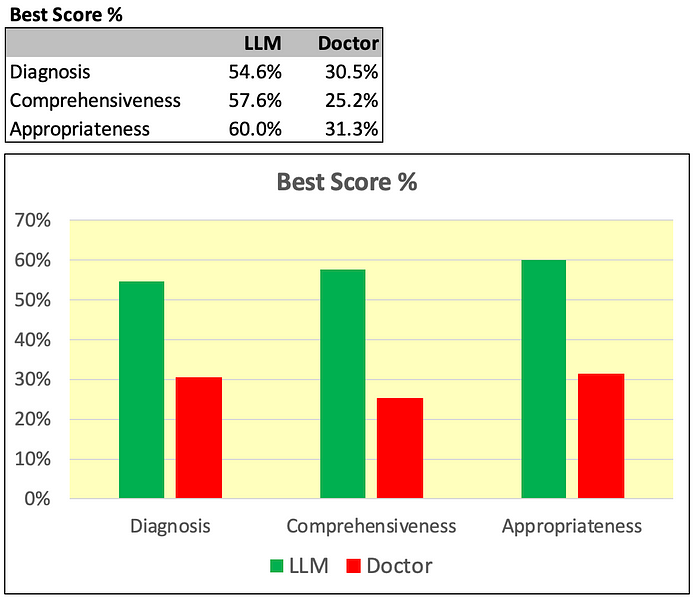
As measured, the performance of the LLM on all dimensions is far superior to the doctors.
Next, I am doing a similar visual representation by focusing on the % of diagnosis that get the worst score.
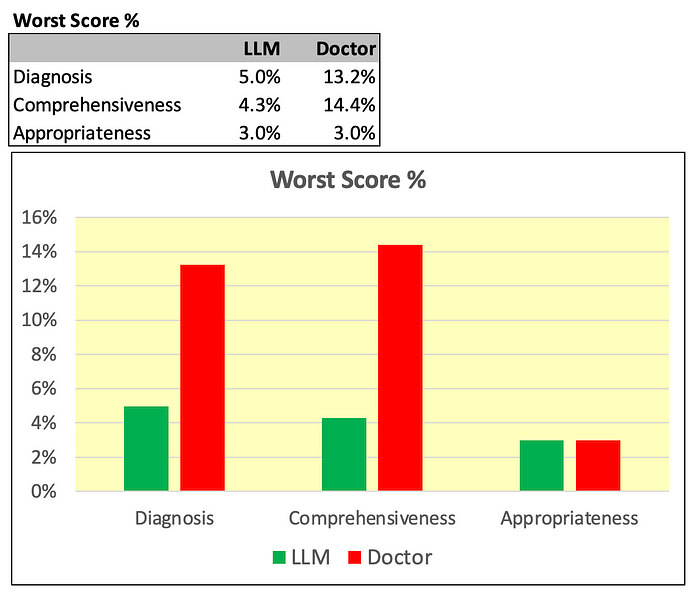
As shown above, on this count the LLM performed far better on two dimensions out of three (Diagnosis accuracy and Comprehensiveness). And, it was tied on the third (Appropriateness).
McDuff paper conclusion
The Chat GPT-4 LLM was far superior to the doctors (unassisted) in making accurate, comprehensive, and appropriate diagnoses. And, the LLM actually much improved the overall diagnostic performance of doctors.
Explaining the different findings
The 3 papers arrive at different conclusions.
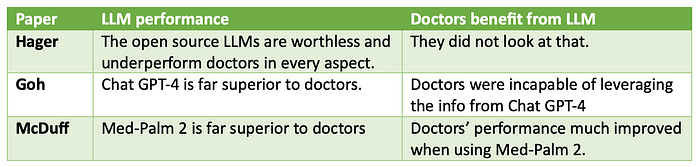
- The Hager paper concludes that LLMs are worthless.
- The Goh paper concludes that Chat-GPT-4 is far superior to doctors. But, doctors are unable to leverage the info from it.
- The McDuff paper concludes that Med-Palm 2 is also far superior to doctors. And, that doctors do benefit from its information.
What explains this divergence?
Doctor testing task
The table below is just descriptive. It does not explain the mentioned divergence.
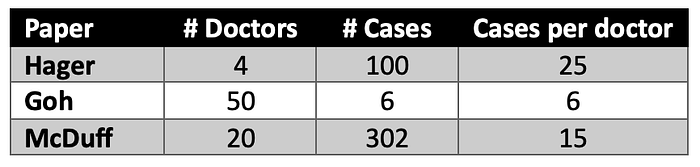
Comparisons
The table below shows how the Goh paper observed more differentiating comparisons between LLMs vs doctors than the Hager paper. And, the McDuff paper observed more such comparisons than the Goh paper.

The above explains why the McDuff paper generated more differentiating outcomes than the Goh paper. And, that the Goh paper generated more such outcomes than the Hager paper.
Power of the LLMs tested
The Goh and McDuff papers used very powerful proprietary models, Chat GPT-4 and Med-Palm 2, respectively. These proprietary models are far more powerful than the open source LLMs used by Hager.

The more powerful proprietary LLMs used by Goh and McDuff fully explain why they both got superior LLM results vs Hager who got very poor results with their weaker open source LLMs.
LLM performance and doctors benefit from LLM
The table below just summarized the findings of the three papers.
Explaining the divergence in the findings
The table below explains the divergence in the findings along two dimensions:
- Power of the LLMs
- Framework challenging level

In summary, the Hager paper used far weaker LLMs and used a much more challenging framework requesting the LLMs to make discretionary decisions. Given that, the Hager paper’s findings are predictably much less encouraging regarding LLM performance vs the other two papers.
The McDuff differential diagnosis framework was more granular than the Goh diagnosis reasoning framework. As a result, McDuff was able to extract an information benefit for doctors using the LLM. Meanwhile, Goh did not.
Reference
[1] Hager P, Jungmann F, Holland R, et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nat Med. 2024. doi:10.1038/s41591–024–03097–1
[2] Goh E, Gallo R, Hom J, et al. Large language model influence on diagnostic reasoning: a randomized clinical trial.JAMA Netw Open. 2024;7(10):e2440969. doi:10.1001/jamanetworkopen.2024.40969
[3] McDuff D, Schaekermann M, Tu T, et al. Towards Accurate Differential Diagnosis with Large Language Models, November 2023, https://arxiv.org/abs/2312.00164

Gaetan Lion is an independent researcher with expertise in economics, econometrics, investments, risk management, statistics, and quantitative analysis. His areas of interest include demographics, economics, investments, Climate Change, health care, sports, and politics.